샤딩(Sharding)
DB 트래픽을 분산할 수 있는 중요한 수단
추가적으로 특정 DB의 장애가 전면 장애로 이어지지 않게 하는 역할도 함
샤딩: 각 DB 서버에서 데이터를 분할하여 저장하는 방식
샤딩은 왜 필요한가?
- 기존의 데이터베이스 시스템은 단일 서버에서 모든 데이터를 처리하므로 데이터 양이 많아질수록 성능 저하나 확장에 어려움을 겪을 수 있음
- 샤딩은 데이터를 분산시킴으로써 여러 대의 서버를 사용하고 병렬로 처리함으로써 확장성과 성능을 향상할 수 있음
수평적 파티셔닝 vs 샤딩
- 수평적 파티셔닝: 동일한 DB 서버 내에서 테이블을 분할하는 것
- 샤딩: DB 서버를 분할하는 것
즉, 샤딩은 DB 서버의 부하를 분산할 수 있다는 것이고, 샤딩을 데이터베이스 차원의 수평적 확장(scale-out) 인 셈

샤딩의 장단점
장점
- Scale-Out이 가능
- 스캔 범위를 줄여서 쿼리 반응 속도를 빠르게 함
- 장애가 샤드 단위로 발생함
단점
- 프로그래밍 복잡도 증가
- 데이터가 한 쪽 샤드로 몰릴 경우(Hotspot), 샤딩이 무의미해짐
- 잘못 사용할 경우 risk 매우 큼
- 한번 샤딩 사용 시 샤딩 이전의 구조로 돌아가기 힘듦
샤딩 종류
1. 모듈러 샤딩(Moduler Sharding)
모듈로 샤딩(Modular Sharding)은 PK를 모듈러 연산한 결과로 DB를 라우팅하는 방식

모듈러 샤딩 특징
- 레인지 샤딩에 비해 데이터가 균일하게 분산됨
- DB를 추가 증설하는 과정에서 이미지 적재된 데이터의 재정렬이 필요함
- 데이터가 일정 수준에서 예상되는 데이터 성격을 가진 곳에 적용할 때 어울림
데이터가 늘어남에 따라 샤딩을 추가적으로 해야하는 상황이 자주 생기면 큰 부하가 발생
데이터가 균일하게 분산된다는 점은 트래픽을 안정적으로 소화하면서도 DB 리소스를 최대한 활용할 수 있다는 것을 의미
2. 레인지 샤딩(Range Sharding)
레인지 샤딩(Range Sharding)은 PK의 범위를 기준으로 DB를 특정하는 방식
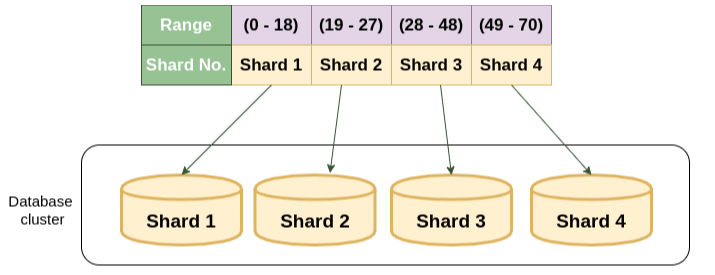
레인지 샤딩의 특징
- 모듈러 샤딩에 비해 기본적으로 증설에 재정렬 비용이 들지 않음
- 일부 DB에 데이터가 몰릴 수 있음
레인지 샤딩은 증설 작업에 드는 큰 비용이 들지 않는다는 점. 데이터가 급격히 증가할 여지가 있다면 레인지 방식은 좋은 선택이 될 것임
활성 유저가 몰린 DB로 트래픽이나 데이터량이 몰릴 수 있음. 그러면 몰리는 DB는 분산시키고 트래픽이 저조한 DB는 통합시키는 과정이 필요함. 따라서 적절한 Range 기준을 잡는 것이 중요
3. 디렉토리 샤딩(Directory Sharding)
별도의 조회 테이블을 사용해서 샤딩을 하는 경우

디렉토리 샤딩(Directory Sharding) 특징
- 샤딩에 사용되는 시스템이나 알고리즘을 사용할 수 있음
- 샤드를 동적으로 추가하는 것도 비교적 쉬움
- 모든 읽기/쓰기 쿼리 전에 조회 테이블을 참조해야 하므로 오버헤드 발생
MongoDB

- 몽고 DB는 다음과 같은 구조로 샤딩을 구성함
- 최소 3대 이상의 호스트를 구성해 하나의 호스트에 장애가 발생해도 다른 호스트로 즉시 복구될 수 있도록 함 = 고가용성
- 3대 이상의 RS(Replica Set, 샤드)을 두어 데이터를 분산 저장함
- 각 RS에는 Secondary DB들을 두어 Primary DB에 장애가 발생해도 Secondary DB를 Primary로 승격시켜 즉시 복구될 수 있도록 함
- 각 데이터의 분산 정보를 구성서버(Config Server)에 기록해두어 mongos가 구성서버에서 데이터를 찾아올 위치를 알아와 처리함
- 각 RS는 주기적으로 OPLog(데이터의 변경사항에 대한 쿼리가 저장되는 별도의 저장 영역)에서 로그를 폴링하여 데이터를 동기화함
- SPOF(단일 장애점)을 최소화함
- 장애 대비를 위해 많은 복제셋들이 대기하고 있어 DB 구성 시 비용이 많이 듦
RDB vs NoSQL
- 이러한 샤딩 데이터베이스는 일반적으로 NoSQL (Not Only SQL)DB 임.
- RDB의 경우, 스키마가 고정되어 있고 정규화를 통한 join 연산을 통해 연관된 데이터를 가져옴.
- 물리적으로 분할된 샤드에서의 join 연산은 많은 어려움이 동반되므로 샤딩은 고정되지 않은 스키마와 정규화되지 않은 데이터가 저장되는 NoSQL DB에서 주로 사용함.
- 더 많은 샤드가 추가될 때 데이터를 다시 분배하는 방식(Resharding)에 대한 처리가 까다로움.
- 특정 데이터에 대한 요청이 몰릴 경우 해당 샤드에 트래픽이 몰리는 HotSpot 문제가 있을 수 있음.
- 모니터링을 통해 트래픽을 파악하고 샤드를 재분배하는 방식으로 해결.
- NoSQL은 비정규화를 통해 다른 테이블에서 데이터를 결합해 가져오는 join 연산 없이 데이터를 key-value 형식 등으로 바로 가져올 수 있고, 샤딩을 통해 데이터를 수평적으로 확장할 수 있음
- 그러나 데이터 변경 시 중복된 모든 데이터를 모두 변경해야 하는 단점 존재
- RDB는 정규화를 통해 중복된 데이터를 별도 테이블에 두어 공간을 절약하고, 변경 시 해당 데이터만을 수정하면 되는 용이성이 있음
- 데이터 조회 시 연관된 데이터를 조회하기 위해 join 연산이 필요함.
- 데이터의 변경이 잦은지 / 많은 데이터가 저장되어 확장이 고려되는지 / 다른 테이블과 join 연산 시 병목이 치명적인지 등을 고려하여 RDB, NoSQL의 사용을 고려해야함.
'데이터베이스' 카테고리의 다른 글
| [SQL] 노선별 평균 역 사이 거리 조회하기 (0) | 2026.02.26 |
|---|